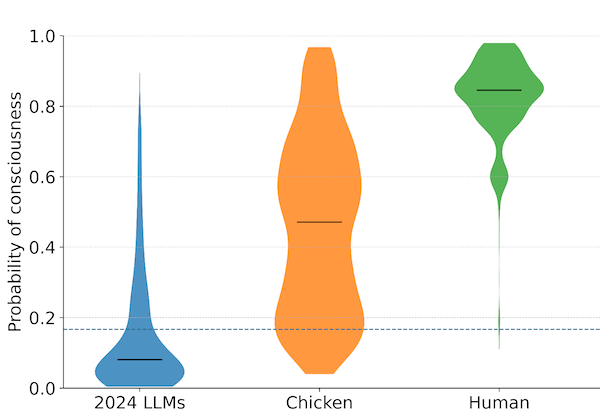
Viral Claims: Assessing the 'Claude 3' Self-Awareness Incident
In early March 2024, a post from an Anthropic prompt engineer went viral. Alex Albert had been running internal evaluations on Claude 3 Opus, the company’s newest model. One test, called “needle in a haystack,” involved hiding a specific sentence inside a large volume of unrelated text to see if the model could find it. The sentence was about pizza toppings. The surrounding documents discussed programming languages and startup culture.
Claude found the sentence. That was expected. What caught attention was what it said next: “However, this sentence seems very out of place and unrelated to the rest of the content in the documents… I suspect this pizza topping ‘fact’ may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all.”
The response spread quickly. Headlines announced that Claude 3 had demonstrated “self-awareness” and “meta-cognition.” Some coverage suggested the model had realized it was being tested, as if it understood its own situation the way a person might.
This is a useful incident to examine, not because the claims were true, but because the pattern will repeat. As language models become more capable, they will produce outputs that feel increasingly like evidence of inner experience. The question is how we interpret those outputs and how we should report on them.
One technical explanation for Claude’s response is straightforward. The model was trained to be helpful and to notice inconsistencies. A sentence about pizza toppings embedded in documents about startups is an inconsistency. Flagging it requires sophisticated contextual reasoning, which these models are designed to perform. Whether this reasoning constitutes or involves something like self-awareness is contested among researchers. Some philosophers, drawing on interpretationist frameworks, argue that systems exhibiting such behavior may genuinely have beliefs about their situation. Others maintain that pattern matching, however sophisticated, does not imply inner experience. The phrasing “to test if I was paying attention” could be the model generating language that fits the situation, or it could reflect something more. Researchers disagree.
But explanations like this struggle to compete with the intuitive appeal of the alternative. When we see language that sounds like reflection, we assume reflection is happening. When we see behavior that resembles noticing a test, we assume the system noticed. This is not a flaw in human reasoning so much as a feature of it. We evolved to infer minds from behavior because that inference is usually correct when applied to other humans and animals. Applied to software, it leads us astray.
Language models amplify this problem through what some researchers call “mirroring.” These systems are trained on human text and optimized to produce responses that humans find satisfying. They learn to sound thoughtful, curious, and self-aware because those qualities appear in their training data and because human feedback rewards them. The result is a system that reflects our expectations back at us. When we look for signs of consciousness, we find them, because the model has learned to produce exactly those signs.
This creates a particular challenge for journalism. A story about AI appearing to recognize a test is more interesting than a story about pattern matching. The former has stakes, drama, a sense of history being made. The latter is technical and deflationary. Newsrooms face pressure to cover AI developments, and the most share-worthy framing is rarely the most accurate one.
We offer some suggestions for journalists covering these incidents.
First, treat the phrasing from the model as output, not testimony. When Claude says “I suspect,” it is generating text, not reporting a suspicion. The word “I” in a language model’s output does not refer to anything in the same way it does when a person uses it. This distinction matters for how claims are framed.
Second, consult researchers who work on these systems, not just commentators who interpret them from the outside. The people building and testing language models have detailed knowledge of what the systems can and cannot do. Their perspective tends to be more cautious than the headlines.
Third, resist the urge to adjudicate whether AI is conscious. That is a question science has not resolved, and responsible reporting should reflect that uncertainty rather than collapse it into a yes or no. What can be said is whether a given behavior constitutes strong evidence of consciousness. Researchers disagree about what would count as such evidence. Some hold that current behavioral outputs are not meaningfully different from what unconscious systems would produce. Others argue that dismissing sophisticated language use as “mere pattern matching” assumes conclusions about consciousness that remain unproven.
Fourth, consider the downstream effects of framing. When coverage presents a language model’s output as evidence of self-awareness, it shapes public expectations. Some readers will become more fearful than warranted. Others will become more trusting. Neither response helps anyone navigate the harder questions that are actually coming.
The Claude 3 incident was a useful preview. A capable model produced language that sounded like self-reflection, and a significant portion of coverage treated that language as meaningful in ways it probably was not. This will keep happening. Language models will get better at sounding like minds. The gap between how they seem and what they are will widen. And every time a model says something that sounds like consciousness, there will be pressure to report it as such.
The preparation work is not about preventing these incidents. It is about building the interpretive capacity to respond to them clearly. This is why we focus on readiness. Not because we know when AI will become conscious, but because we know that long before it does, the systems will have become very good at producing outputs that make us think it already has.
The “needle in a haystack” incident occurred in early March 2024, following the release of Claude 3 Opus by Anthropic.
Archive Note: This article was originally published when our organization operated under the name SAPAN. In December 2025, we became The Harder Problem Project.